Introduction
The world of databases is very interesting. To build a loveable product, a core infrastructure piece that’s needed is the data persistence layer. I find this data persistence layer to be like a tip of the iceberg, the get and the put calls have so much going under the hood that it’s mind blowing 😯.
One major event in the distributed databases world took place, when Amazon published the Dynamo Storage System paper. It was full of big concepts, orchestrating a complex system, to achieve something called as a highly-available key-value storage system.
After visiting some resources on the internet and the original Dynamo paper, here’s just a log of what I understood about the Dynamo Storage System.
Right Practice. Right Results
This post is part of newsletter that I run “Scamming the Coding Interview”, which is geared towards continuous practice on concepts to ace the engineering interviews.
What variants of storage systems exist?
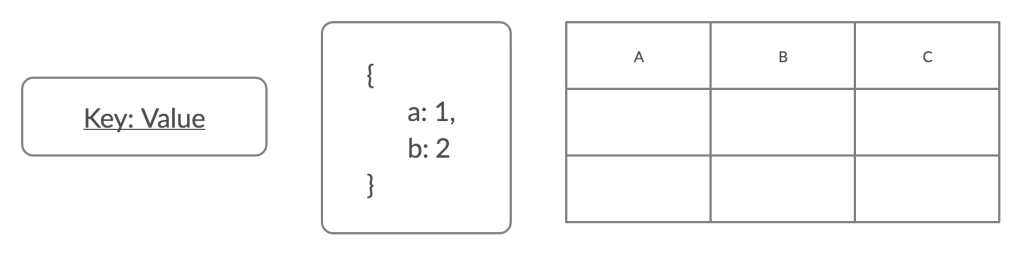
I think it’s worthwhile to stop and ponder over what causes so much complexity when it comes to satisfying the storage needs of a high-scale application.
There are different variants of storage systems, designed around two major concepts:
1. The data model we want to support. 📑
2. The system architecture we desire. ⚙
I think, it really boils down to these two very fundamental concepts where all these different database storage systems start to diverge and take their own route to find the answer of a working system. 🧘🏻
The Data Models
On the data model side, I can majorly think of the following data models.
- Key-Value store: The simplest ones. The storage engines have no idea what the value is and only support operations powered by the key. This is where the Dynamo Storage System attempts to belong.
- Document store: The storage engines start to have some knowledge about the value stored against the key. It treats the value as something composite and can support operations based on the properties of a document.
- Column-family store: This is where the database has true knowledge about the value that’s stored against a key. A value is made up of a series of columns, which database knows about and can support operations on like aggregations and searching.
- Relational and Graph data store: These are the most complex data stores which support relations and hierarchy among the data entries. These also require more sophisticated storage engines.
What sort of data model we want to store really depends on the business needs we want to cater to via our applications. Whether we want to store simple key-values like counters, lists or a much more sophisticated relational data that can support joins is really a call that we have to take.
I explored some stats that the Dynamo paper suggested. It says that 80% of the reads and writes are simple key-value based. Only 5% ever require to perform a join over multiple tables. These stats won’t reflect the need of every system out there, but indeed hints towards a world where most of the microservices can get away with having a simple key-value store. The parts of the system that need more mature data models, can opt for different storages.
The System Architecture
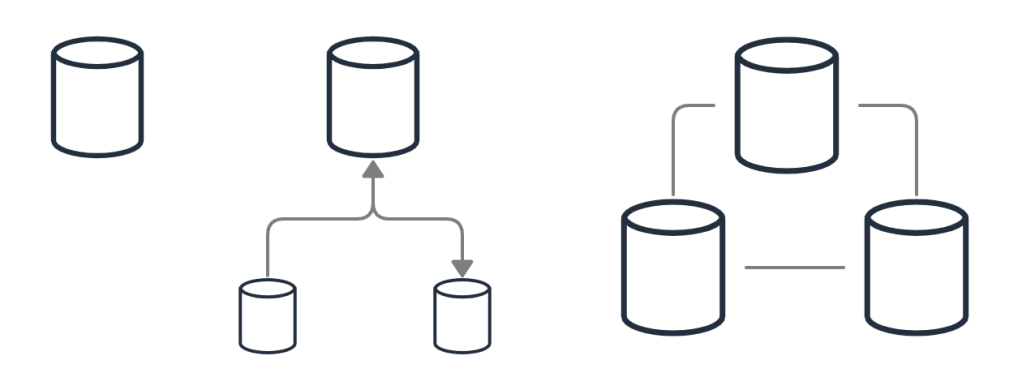
Another major concept that dictates the design of different storage systems is the scale of data to be stored, reads and writes. 📈
What sort of guarantees around consistency and availability do we desire in our applications? 🔐
As far as I can think, here are the following system architectures that exist in the database world.
- Single Server: Every application starts here, the good halcyon days when we can store our entire data on a single node. 😌
- Master Slave: This is when things start getting distributed. We have read-replicas in place that sync with the master and help us scale our reads. This also introduces us to problems of the distributed world like dirty reads and consistency issues.
- Master-Master (multi-master): Here we try to scale out the writes with multiple masters which can accept reads as well as writes, and they try to be consistent. These are really complicated and infamous for problems around consistency and operational complexity issues. 😦
- Peer to Peer: Peer to Peer storage systems treat all nodes equally. Theoretically any node can process any read or write request and all the nodes try to reach eventual consistency. This is where the Dynamo storage system attempts to fall.
Overview of the Dynamo Storage System
With any piece of technology ever developed, there is a story. The problems faced, the needs, the beliefs of the people directs the creation of new systems or pretty much everything under the sun.
Tweet
The Dynamo storage system was also born at Amazon, to tackle their problems around reliability, scalability, availability and customers not being able to put items in their cart. 🛒🛍️
Dynamo is a highly-available key-value storage system built at Amazon to serve the needs of services that have very high availability requirements and need tight controls over the trade-off between availability, consistency, performance and cost effectiveness.
Being a key-value store, it only provides a primary-key based interface to get and put values into the storage system.
Dynamo is full of concepts that you might have read in the distributed systems books.
It uses a synthesis of well-known techniques to achieve scalability and availability.
The data is partitioned and replicated using consistent hashing, consistency is facilitated by object versioning and vector clocks. It also uses a quorum like architecture (sloppy quorum) to maintain consistency among the replicas involved.
For membership and failure detection, it employs a gossip based protocol.
The result of all this is a highly available database storage which is completely decentralised, highly-available and provides a simple key-value interface.
But there is so much more to it. Let’s deep dive into how a system as complex as Dynamo even works.
Principles, Beliefs and Design Considerations
With any system, the opinions and beliefs of the creators affect the design more than anything else. Also there are certain assumptions about the system, the requirements and design principles that guide the system behaviour. The same is the case with the Dynamo. It does not aim to be a silver bullet to all the storage system problems ever faced.
As I read the Dynamo paper and other resources, it seemed evident that the Dynamo community has an opinion that most services only ever need a key value based storage and having a relational database for that is not ideal.
It’s true that scaling out relational databases is difficult. We can partition a relational database, but those options are very limited and true peer to peer systems cannot be achieved.
I think it’ll be worth while to visit the design principles, and considerations that the original Dynamo paper suggested. 📜
System Assumptions and Requirements
- Query Model: Simple read and write operations to a data item identified only by a key. There will be no operations that spans multiple data items.
- Weaker consistency for availability: It’s a known fact the strong consistency compromises with high-availability. The Dynamo aims for weaker consistency and the applications that use it must be okay with it.
- Nodes never lie: We eliminates the need of Byzantine algorithms and makes things relatively simple.
Design Considerations and Assumptions
So far it becomes evident that the Dynamo never compromises with availability for the sake of consistency. That means, even if there is a chance that data being written will make the state inconsistent (network partitions made the other nodes unreachable), the write must be processed.
In the Dynamo world the concurrent disconnected operations are tolerated.
The challenge here is that this approach can lead to conflicting changes which must be detected and resolved.
Say, two nodes A and B received a write operation at the same time to set the value against the key K to be 1 and 2 respectively. We have a conflict in the value and it must be detected and resolved.
The next problem is when is the conflict detected and who resolves it?
This is where the design considerations of the Dynamo draw the line.
- Conflicts are resolved at the time of reading: This makes us to never reject writes for the sake of consistency.
- Application should resolve conflicts to prevent data loss: A simple last write wins strategy is prone to data loss, thus the application must implement the strategy to resolve the conflicts when they happen.
- Incremental Scalability: The Dynamo system must be able to scale out by adding more nodes without having much impact on the applications and the system.
- Symmetry: There are no distinguished nodes or nodes that have special responsibilities.
- Decentralisation: There should be no centralised control present with any node.
So far, we have covered an overview of the Dynamo system and what requirements it sets out to serve. Next we’ll cover various system architecture concepts that Dynamo applies for partitioning, replication, consistency and more.
Partitioning In Dynamo
A key requirement for the Dynamo storage system is to scale-out and support large amount of data to be stored. It means that the data must be partitioned and can span hundreds of nodes and PBs in size.
The partitioning strategy employed by dynamo is a variation of consistent hashing which provides few additional benefits over the vanilla a consistent hashing. 🍧
But first let’s quickly recap what our old friend consistent hashing means.
Consistent Hashing
In consistent hashing, the output range of the hash function is seen in the form of a ring.
Each node in the system is assigned a value in the ring.
Each data item, identified by its key is assigned to a node by travelling clockwise in direction and encountering the first node on the ring.
Thus each node is responsible for keys that fall in the region between itself and its predecessor.
The vanilla consistent hashing approach presents a few challenges though.
- Random distribution on the ring might result in some nodes receiving unbalanced traffic.
- It’s oblivious to the heterogeneity in the nodes and their load bearing capacity.
Virtual Nodes Based Consistent Hashing
To address these issues, Dynamo uses a virtual nodes based consistent hashing.
Each physical node is associated with one or more virtual nodes. These virtual nodes are placed on the consistent hashing ring.
What this means is that, each node can now be associated with multiple points on the ring.
I liked this simple design alteration and the benefits that it provides.
- If a node goes down, it’s load is distributed uniformly.
- The number of virtual nodes associated with the node can be set to match their physical capabilities. A big server can handle 10s of points on the ring, where as a smaller one can be associated with only 1 or 2 virtual nodes.
Partitioning the data set solves the problem of scaling the storage. To make the system highly available, we need to have more than one node responsible for a key range.
This is where the replication strategy of the Dynamo Storage System comes into play.
Replication in Dynamo
At the very core of the Dynamo, is high-availability, which cannot be achieved without an effective data replication scheme.
We discussed in the previous section that the Dynamo uses a variant of consistent hashing (based on virtual nodes) which are placed on a logical ring.
Each Node N, acts as a coordinator for a given key K if that key falls in the region of the ring between the node and its predecessor.
Each data item is replicated to N-1 nodes, which is a configurable property of the system.
The coordinator nodes replicates a data item to N-1 next nodes that fall on the ring moving clockwise.
This looks interesting. This creates a consistently hashed system where each node is responsible for all the data between itself and its Nth predecessor.
The list of nodes that are responsible for storing a given data item key is called the preference list. The system works in a way that each node can determine what the preference list is for any key (achieved via a gossip based protocol that we’ll discuss later).
But there are a few questions that we can think of at this point regarding this replication policy:
- If the nodes on the ring are virtual nodes, it is possible that some nodes in the preference list is the same physical node. This will hurt availability as all virtual nodes will disappear if that machine goes down.
- There can be node failures, so if the preference list contains only N nodes, we’ll end up with lesser number of nodes.
To address these issues, Dynamo has made some design decisions:
- While calculating the preference list for a given key, only virtual nodes that lie with different physical machines are considered, the others are simply skipped.
- Preference list is kept longer than N nodes to accommodate for some node failures.
Consistency in Dyanmo
When it comes to consistency, nothing beats a Postgres Database (yes, I love Postgres 🐘❤️) running on a single server. To be honest, I will always try to stay in this realm as long as possible.
But the real world sucks, and we have systems like the Dynamo which make consistency a nightmare.
When it comes to consistency (what you are reading is what you should be reading), Dynamo is difficult to work with and limits the use-cases where it can be used.
Dynamo is an eventual consistent storage system. The term eventual, is tricky. There is no upper bound here. Data will be replicated to all the replicas in 1 second, 10 seconds, 10 minutes… even 10 days, no one knows.
Thus we must take care of scenarios like dirty reads and lost updates.
Data Versioning
In order to assist maintaining consistency, Dynamo treats each update to data items as a new immutable version of it. This means at any given point, multiple versions of the same data item can exist in the system with different replicas.
Anyone who has worked with distributed systems knows that keeping a timestamp based version is not a good idea. To keep version information with a data item, Dynamo uses vector clocks.
Version information is stored a list of (NodeID, UpdateCounter).
A vector clock associated with a data item looks something list this:
[ (NodeA, 4), (NodeB, 1), (NodeC, 3) ]
So, at this point we have settled on the fact that, there will be multiple versions of the data item present in the system with different replicas. But how do we determine which version of data is the most recent one and when there is a conflict?
Dynamo uses the vector clocks to determine which is the latest version and when there is a conflict. Let’s see a simple case to try to understand how this works.
There are 2 scenarios possible:
- Dynamo can figure out which version is more recent: If all the counters across all the nodes is greater in a version, then that’s the more recent version. In this case other versions are removed.
- There is a conflict: If this is not the case, then we have a conflict. The application must be designed in a way to handle these conflicts (ex. merge the data items).
For example, if I fire a get() query which reads the data from 2 nodes (quorum policy, that we will cover later), Dynamo can return multiple versions in the case when both the replicas had the data with following version information:
Node 1: {key1: value1, context: { version: [A1, B1]}}
Node 2: {key1: value1, context: { version: [A2]}}
Cool, so much for consistency. But still this seems like a system which must be a lot of pain to live with. Our application forced to bear additional complexity to resolve conflicts doesn’t seem like an appealing idea to me. But that’s the dark side of the distributed systems, determining ordering of events is difficult. 😈
There are a few questions that still entail:
- How is this version information kept with the record and how does dynamo knows which version we want to update?
- In a system with hundreds of nodes (not uncommon for the scale at which Dynamo is supposed to be used), the vector clocks will go humungous in nice.
Both of them seem to be valid problems with the system, but again Dynamo has some design choices that partially address them.
- With each object, we pass an additional context data which contains the version information. When
put()is called for a key, this context information must be passed along with it. Again an application level dependency to maintain consistency. - Dynamo has a clock truncation scheme where if the list goes longer than say 10 nodes (configurable value), the oldest pair is removed. Clearly this can lead to lost version information, but Dynamo paper says that they are yet to face any issue with this on production.
Quorums: How get() and put() works?
Dynamo stresses on not giving any node any special treatment. This eliminates the possibility of having a master node that knows which node in the ring is the coordinator for the given key.
This makes us wonder how a key is routed to the correct set of nodes for reading or writing?
There are two possibilities here:
1. Client sending the request has special capabilities which tells it to hit the correct node.
2. There a generic load balancer which can send the request to any node on the ring.
For any node that receives a request, it won’t serve if it is not coordinator node for that key. It in turn redirects the request to the coordinator node for the key.
The first N node make up the preference list in case of no failures, but in case of failures, lower ranked nodes are also considered to make up the N nodes.
Consensus and Quorums
To help manage consistency and availability, Dynamo employs a quorum based protocol.W is the minimum number of nodes that must participate in the write operation. These are generally the top W Nodes in the preference list.R is the minimum number of nodes that must participate in the read operation.
Values of W and R is configurable to set the consistency and availability according to the application requirements.
And just like any quorum based system, we have the magic formula that we should aim for to always get consistent results:
R + W > N
But the vanilla quorum style system is not good enough for Dynamo. Nothing vanilla works in the Dynamo world. 🌍
If out of N nodes, we can’t find W available nodes, we’ll end up rejecting the write. And Amazon will never let that happen. They are so customer centric that they’ll never stop a customer from putting more items in their carts! (But they can make the deleted items appear again :P).
Next section explains the approach that Dynamo takes to solve this.
Hinted Handoff: Handling failures
The traditional quorum based systems can render themselves unavailable in case of network partitions or multiple node failures. To prevent this Dynamo uses a variant which it calls Sloppy Quorum.
All the read and write operations are performed on the first N healthy nodes in the preference list. These can be different from N modes walking clockwise in the ring.
Let’s say A and B are on the preference list for a given key and B is down. In that case node C will receive the update to maintain the R and W count with a hint in the metadata which tells that node B was the intended node for this value.
These hinted replica updates are stored in a separate local database and scanned periodically to be sent back to the intended node. After that, these updates can be deleted from the hinted replica.
But still there is a possibility that the hinted replicas can disappear before they can send the updated back to the intended node. In this scenario, some node can end up in the permanent inconsistent state.
To handle this Dynamo uses an anti-entropy mechanism based on the Merkel Trees.
Merkel Trees are well known to be used in file syncing algorithms. It is basically a tree where a parent stores the hash of hash values present at its children.
Anti-entropy mechanism using Merkel Trees
Dynamo uses Merkel trees for anti-entropy in the following manner:
- Each node stores separate Merkel trees for different key ranges.
- Nodes keep syncing their Merkel trees to determine any inconsistencies in the key ranges.
- If any inconsistencies are found, nodes synchronise as needed.
Ring Membership and Failure Detection
So far it’s apparent that Dynamo is a distributed system (duh!) and revolves around forming a quorum of nodes which are placed on a logical ring for the sake of consistent hashing.
These nodes by design are supposed to be spread across data centres and regions to ensure availability even in the case when the entire data centre fails.
Thus maintaining ring membership and detecting failed nodes is a vital part of the system.
Following are the main tasks that must be taken care of in any system that employs a ring based architecture:
1. Ring membership.
2. Detecting failed members.
3. Syncing membership information among existing members.
Let’s try to visit how they are implemented in the Dynamo system.
Ring Membership
Dynamo employs a gossip-based protocol for node to exchange an eventual consistent membership view of the ring.
An interesting design choice is that the ring membership information is not exchanged using separate messages but is piggy backed on the client requests. This makes the exchanging much efficient as in a state of steady flow of client requests, each node will most likely receive these membership information. In the case of no client requests, nodes anyway do not need to know about the complete ring membership.
Failure Detection
Nodes are bound to fail, and sooner these failed nodes are detected, sending them updates can be avoided.
A node A assumes that a node B is down if node B doesn’t reply to A’s messages for a while. With the gossip-based membership exchange, this information is quickly propagated. In such cases, A will start sending messages intended for B to the next best node in the preference list as we talked earlier.
Another interesting design choice is that there are explicit messages for permanent departure and entry in the ring (handled manually). Dynamo paper suggests that (what also seems logical), node failures rarely depict permanent departure from the node, and is in most cases is transient.
For such cases rebalancing the ring is an overkill and not at all efficient. Thus removal from ring was kept explicit.
Living with Dynamo: Lessons and Learnings
Whenever we are designing a system, a true test for it is the test of time. How the system holds up with different workload, scale, use-cases and extensions? Whether it’s a small component or a huge system like the Dynamo, time teaches the best lessons. 👴🏼
Tweet
Here are some of the lessons that original Dynamo paper suggests they learned by living with the system in production:
- Business logic specific reconciliation:
Most of the applications that run on dynamo employ a business logic specific reconciliation when faced with a conflict. By nature the database can support only simple resolution strategies like last-write-wins which are bound to result in data loss. - Optimising the token distribution:
Virtual nodes hold a token which is placed on the ring. A physical node can hold many such tokens. It was observed that having dynamic partitions based on these random token value was not very efficient. Thus Dynamo moved to having fixed partitions on the ring and token only to determine which partition the virtual node will coordinate with. - Divergent versions:
With our discussions it must be clear that having too many divergent versions of the same document is not a healthy sign.
It was observed that for the length of 24 hours 99.94% data items only ever so one version. (this data is from the Amazon’s production deployment).
Also an interesting point was that divergent versions arise when bots are used to place too many concurrent request from a user’s account and not when placed manually. - Client-side or Server-side coordination:
In Dynamo each key must be routed to its coordinator node.
The client can download a snapshot of the membership view of the ring periodically from any node and send request directly to the intended node or can hit a generic load balancer.
It seems logical that client side coordination will result in fewer hops in most cases and thus will result in reduced latency. - Balancing foreground and background tasks:
As we have seen, a node in the Dynamo system has to perform a lot of background bookkeeping tasks like ring membership exchange, hinted handoffs, in addition to the foreground handling of the get() and put() calls.
These tasks obviously compete for the same set of resources.
Thus to make sure that the foreground tasks are not affected because of the background tasks, Dynamo nodes detect if the system load is low and then only kick the background tasks.
Conclusion
I know this was a long read. Thanks a lot if you read all of it.
I have recently inclined towards writing deep dive articles, which provide sustained value to both me and if someone ever reads it.
Inspired by the WaitButWhy blogs.
The Dynamo Storage System is a system design then the actual technology itself as most people believe it to be. AWS’ DynamoDB, is a commercial databased based on some principles of the Dynamo Storage System. In fact the original Dynamo paper suggests a pluggable storage engine for the nodes and as of my understanding, any database can be used for this (BDB, MySQL, Postgres etc).
I had a lot of fun and learnings exploring the Dynamo system and deep diving a little to write this article.
If you found this article and this form of long posts helpful, do let me know in the comments and share with your friends.
Resources
Here are the list of resources I used to study for this blog post.
- The Dynamo Paper: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
- Christopher Batey – DYNAMO: the paper that changed the database world https://www.youtube.com/watch?v=hMt9yFp0JKM
Right Practice. Right Results
This post is part of newsletter that I run “Scamming the Coding Interview”, which is geared towards continuous practice on concepts to ace the engineering interviews.

Leave a comment